
I overheard - over-read, really - an internet discussion about database storage engines. The discussion was about what functionality is considered part of a storage engine, and what functionality is in the common parts of the database server. My first reaction was something like "how isn't this obvious?" Then I realized for a lot of the database functionality it isn't obvious at all and the answer really is that it could be either way.
In this blog post I want to cover what I know about storage engine APIs. I have worked with the two databases most known for their storage engine API: MySQL and MongoDB. On the other hand I have never actually written code to implement a storage engine, I just used lots of them and tried to understand their general history. So corrections and additional details are welcome in comments.
On the other hand, I'm the only person in the world who has organized both a MySQL and a MongoDB storage engines summit. So those are my credentials for writing this blog post.
Since it turns out there is no one true way to do a storage engine API, perhaps it is useful to start with a historical overview of how these APIs evolved to "do what needs to be done" at different points in time.
MySQL Storage Engine API
If you read up on MySQL history, or have Monty tell it over dinner, you'll know that before MySQL, there was the Unireg database. In the early 80's SQL didn't yet dominate the database landscape, so the forefather of MySQL was in fact something resembling a storage engine! It was only in 1995, in response to user demand from the web development and open source communities, that TcX Datakonsult added a SQL frontend and TCP/IP server. Still today you can find functions like unireg_init in the MySQL storage engine API. This was when the product name MySQL was introduced, and as I'm writing this, some of my friends on social media are therefore congratulating MySQL for its 25 year birthday!
When I asked Monty about how the storage engine API was invented, his response was that it was always there. To improve the database functionality, it was sometimes necessary to also change the data format on disk.1 To support backward compatibility, new MySQL releases would ship with two different storage engines: the old version and the new version.
The storage engine API became more of a thing when MySQL partnered with InnoDB to gain a proper transactional engine. Now users were very much aware that certain features were only available in the non-default engine.
Finally, the story around the storage engine API became part of a defensive play, when Oracle acquired both InnoDB and BerkeleyDB, both of the transactional MySQL engines available. MySQL scrambled to attract lots of different engines, including NDB and Falcon developed by MySQL themselves. The message to customers was that you needn't worry if Oracle owns one (or two) engine(s), because there are so many to choose from.
In hindsight, none of these engines were ever an InnoDB replacement, but the message did attract a lot of interesting engines that MySQL users could choose from. Thanks to this ecosystem I was early on familiar with a clustering row based engine, an index+log engine, an LSM (or "fractal tree") engine, a distributed engine, a text search engine, a key value engine, a columnar engine, a graph engine, and an active-active (RAC like) engine. The MySQL ecosystem was like the whole database industry in a microcosm.
People who worked closer to the MySQL storage engine will tell you that it's not this nice and well documented thing that I can write an enlightening blog post about. Around the time I worked there, 12 years ago, the API was described as mostly the MyISAM API that someone had shoved transactions into as an afterthought. And then of course there were traces of unireg code here and there, that most people probably had no clue what that was about.
MongoDB
While MySQL was where I learned about storage engines, at MongoDB I was the one pushing for the idea of a storage engine API. Initially this was met with much resistance, but 18 months after I started working there, MongoDB acquired the WiredTiger storage engine.
MongoDB as a company didn't embrace an ecosystem of 15 different storage engine partners, but was always focused more on being its own turn key solution. In fact, MongoDB has been so focused on the WiredTiger engine that they even removed the original MMAPv1 engine two years ago. At MySQL there was always a need to keep MyISAM engine around.
That said, there were a few 3rd party engines that integrated with MongoDB: Tokutek and RocksDB were the most well known, and they have had a handful of users. (Which frankly, is the same amount most MySQL engines had too!) Even just a month ago Micron has published a new SSD and NVM optimized engine that integrates with MongoDB.
The MongoDB API is said to be cleaner and clearer than its MySQL predecessor. Even then, it is not free from traces of its evolution either. In the MMAPv1 engine, records were referenced directly with their memory addresses. (Which you can do when you mmap the database files into memory.) As a result of this, still today the storage engine API operates on records identified by a 64 bit integer. (Which for the MMAPv1 engine happened to work as a memory address.) This means that also in the WiredTiger engine, MongoDB uses an internal, hidden primary key index. WiredTiger could support also a clustered primary key (meaning, the record data is stored in the leaf of its primary key entry) but the MongoDB storage engine API doesn't support this. So in MongoDB, the _id field is semantically your primary key, but inside the database it's technically more like a unique secondary index. The real primary key is a hidden 64 bit integer.
An interesting part of the MongoDB storage engine API has been the evolution of distributed transactions support. While WiredTiger always supported transactions, additional integration is needed to support distributed transactions. For example, the storage engine must be able to accept transaction id's (oplog timestamps) generated elsewhere in the cluster, and it must be able to serve specific MVCC snapshots as requested by the MongoDB layer. For sharded transactions it must support Two Phase Commit (2PC).
So what's in the storage engine really?
For all the talk about storage engine APIs, you'd think this question has a well defined answer. Turns out: no.
Of course, a storage engine is responsible for storing records to disk. Except of course if it's an in-memory engine! But most engines store to disk. The engines that store data to disk also need to write a transaction log (aka journal). Except if they are called MyISAM, of course. This is an integral part of the storage engine, since the journal is key to providing ACID properties. For some database engines, the journal and the data files are one and the same! This is the case for PrimeBase and BerkeleyDB Java Edition, for example.
If we approach the topic from the historical perspective, then "the storage engine" was whatever functionality was provided by MyISAM and especially InnoDB. (It was even said that the InnoDB source code is the documentation for the MySQL SE API.) This included secondary indexes and foreign keys, transactions and the concept of tables and columns.
But, BerkeleyDB of course is a key-value database, which has neither columns nor secondary indexes. So how does that work? And by the way, WiredTiger in MongoDB is the same. (Not surprising, as these two database engines were created by the same people.) As is RocksDB, another popular storage engine.
It turns out, when MySQL and MongoDB use key-value storage engines, then secondary index functionality has to be built on top of these engines. In practice the secondary index is a separate table, whose "row" value is the primary key of the record. Since all of the aforementioned key-value engines are transactional, it is then possible to update the primary key table and secondary index tables atomically. And by the way, this is exactly how InnoDB secondary indexes work too (they point to the primary key values) the only difference is that InnoDB handles this for you, while with key-value engines you have to do the work outside the engine.
With a key-value engine, the server level also has to handle the concept of columns (or in MongoDB's case, BSON documents) and data types. In the case of a more full blown database engine, the engine has to map its own data types to those supported by the query language of the server. (e.g. Tinyint, Bigint, Varchar, and so on...) If we summarize what we have learned so far, we can draw the following architecture diagram:
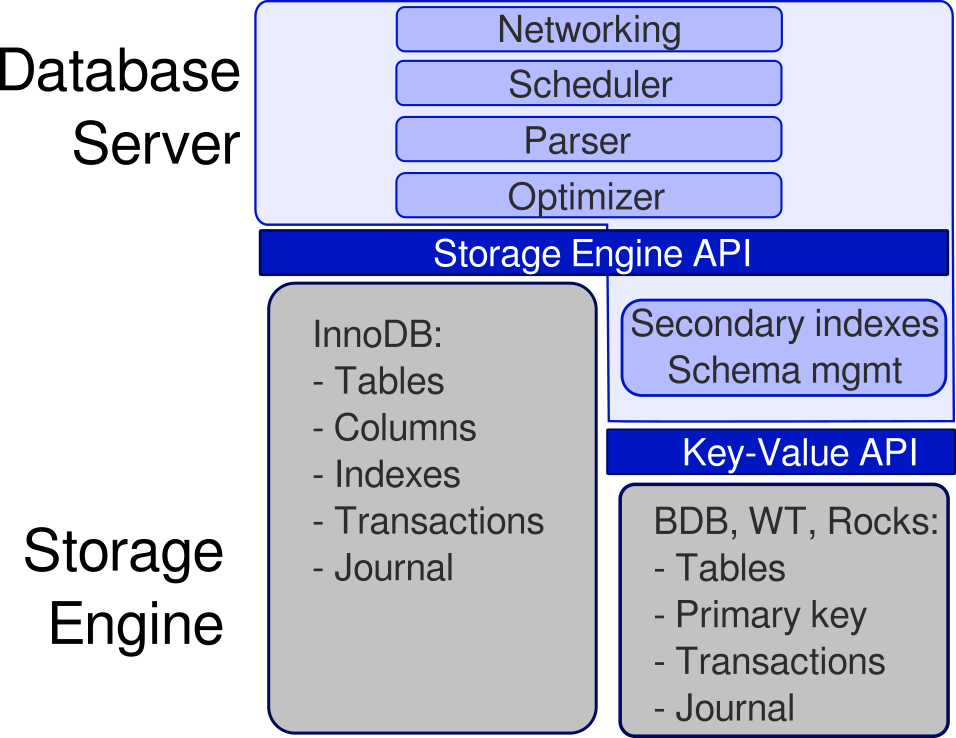
Both for MySQL and MongoDB, the key-value API was, in fact, the BerkeleyDB API. It's industry standard, and also RocksDB and WiredTiger implemented it.
XA transactions
MySQL supports multiple storage engines at the same time. Each table can have a different engine. If you actually do this, transactions become a challenge. Each engine does transactions, and journal them, in their own way.
The solution here is that transactional engines need to support XA transactions (two phased commit) so that they can commit transactions together. Originally this created performance issues where optimizations like group commit weren't possible if you actually tried to use a mix of storage engines.
MongoDB allows only one storage engine at a time, you select it at start of the mongod process. You could however mix different engines in a replica set or sharded cluster. In practice >99% of users use InnoDB and WiredTiger. So the overhead from the MySQL way isn't very justified.
Reading data
The above wasn't so bad. There are two APIs instead of one, but it's still quite simple to understand. If only real life was that simple...
Both MySQL and MongoDB assume a row based model for the storage engine. When processing a query, the optimizer will open a cursor either on the data table directly, or a secondary index. It then iterates over records and index entries one by one. But even for some row based database engines, this is a poorly performing strategy.
MySQL NDB Cluster is a distributed database, where data is stored on separate servers, and the MySQL server is essentially just a proxy, much like mongos nodes in a MongoDB cluster. While fetching one row at a time from InnoDB is an efficient strategy, doing one network roundtrip for each record is terrible. Due to this, first version of MySQL cluster was essentially only useful as a key value store. Later MySQL versions extended the storage engine API so that the server layer could ask for a batch of records at once, and eventually push down the query predicates and join conditions altogether. Jonas Oreland gave a great talk comparing the performance of these three alternatives with fetching bottles of beer from the fridge while watching football: The row based approach is like fetching one bottle at a time. The batch approach is like fetching a whole case at once. And the push down approach is like moving the coach and television into the kitchen!
MySQL has a cost based optimizer. This means it will sample all tables to estimate what kind of data is stored in each table, then deduce from there which index is the most useful to read from. But, as we already concluded, the cost to read one index key, or the cost to read one record, is not the same for all engines. (In fact, that's kind of the point of having different storage engines.) Assuming that the optimizer is not part of the storage engine, then it should still allow the engine to supply a cost model that is correct for the particular storage engine. As far as I know, MySQL still doesn't do this? Back in the day I remember that NDB engine would lie about table statistics to force the optimizer to prefer specific indexes. And let's not forget about the parser...
Some storage engines support transactions, others don't. MySQL had the (not so) user friendly solution to silently ignore commands not supported by a given engine. So you could do a BEGIN ... COMMIT against a MyISAM engine and not get an error, but your writes of course would not be transactional. MongoDB removed the non-transactional MMAPv1 engine altogether. We definitively preferred the latter path!
Some engines may support RTree indexes, full text indexes... The parser has to support all of these. So each time an engine added new capabilities to MySQL - graph queries, say - the parser had to be extended. Maybe allowing engines to dynamically extend the parser would be a good idea too?
The extreme case was Infobright, a columnar storage engine. Fetching the result set row by row is of course anti-thetical to the whole point of a columnar engine, and would perform poorly. At least the first version of the Infobright storage engine simply bypassed all of the MySQL parser and optimizer. It would intercept the whole query before the MySQL parser, replace it with a SELECT * FROM temptable, internally use its own parser and optimizer to process the query, execute the query, put results in a table called `temptable`, and from there MySQL would return the results to the client. Not elegant, but a good example of how hard it is create a general purpose storage engine API that supports any imaginable (and not yet imagined) engine.
So as a summary, whether something is better done inside the storage engine or above it, is not an easy question to answer.
Replication
The one thing we agreed up front was that at least the transaction log is part of the engine. I'm afraid I have bad news...
Replication also uses a log of transactions. It is separate from the storage engine's own transaction log and for both MySQL and MongoDB the replication machinery is above the storage engine. In MySQL the "binlog" is a separate file - a binary log. However, it must participate in the commit. Essentially it acts as yet another storage engine participating in the XA commit. As said above, this used to have severe performance cost, but eventually some smart minds figured out how to do XA group commit.
In MongoDB the "oplog" is a collection. So it is managed by the server layer, but actually stored by the storage engine. This is convenient in many ways. Atomic commit is simple and as a bonus the user can query the oplog to see their own transactions! On the downside, a B+Tree is a terrible data structure to use for a log. In practice both the MMAPv1 and WiredTiger engines implemented the oplog in a special way.
Storing the oplog inside the storage engine also means that the same data is now stored 4 times! 1) In the collection itself, 2) which is journaled, 3) then in the oplog, 4) which is also journaled. Recent versions of MongoDB have optimized away write #2. This means that the data files are no longer durable, rather WiredTiger only guarantees that the oplog is durable. MongoDB layer is then responsible for replaying the oplog so that missing data is added back to the collection files. It would be possible to also not write the oplog twice. In practice this would mean that the WiredTiger journal and the replication log are the same thing. Whether such a log is part of the storage engine or the replication code is a matter of philosophical debate.
Synchronous replication
MySQL offers a few synchronous replication options. These intercept transaction result sets at commit time, block the storage engine from committing while they do their thing, and eventually allow the commit to succeed or abort. Whether or not this is implemented as two phase commit, that's essentially what it is.
Image credit: New Slant, Designed by Haldane Martin, Photo Jan Verboom CC-BY
- 1If you've taken computer science classes in college, you've probably taken a course called "Data Structures and Algorithms". It's not a coincidence those things are always in the same course. A given algorithm typically dictates a specific data structure. You can't have one without the other. And this is why databases have different storage engines.
- Log in to post comments
- 2130 views
oplog and Tungsten Replicator
Henrik,
Your favorite swans here... Quick question: As you know, Tungsten Replicator is an advanced MySQL replication solution with filtering capability and ability apply to multiple heterogeneous targets, among other MongoDB and MongoDB Atlas. From time to time we have got requests from our customers to be able not only to replicate from MySQL to MongoDB but also to replicate back from MongoDB to MySQL. Do you think this would be feasible using 'oplog' similar fashion as we take MySQL 'binlog' and convert that on the fly in our own generic THL (transaction history log) format? Are there any known MongoDB replication solutions available doing this? Eero
Hi Eero
It is possible, but several years ago MongoDB has already productized Change Data Capture, which is a friendly API on top of the oplog. See https://docs.mongodb.com/manual/changeStreams/