I work for a company that is the leading supplier of automotive maps, and wants to be the leading supplier of online maps. So it was only a matter of time that I needed to learn more about how spatial extensions work in different open source databases. Let's start from the beginning, understanding various spatial data structures that are used in implementations...
Links are provided to Wikipedia articles - which are both comprehensive, yet easy to understand - for those who want to get a deeper understanding of each structure. All Wikipedia articles on spatial indexes are listed here: https://en.wikipedia.org/wiki/Spatial_index#Spatial_index
B-tree
The B-tree (and its variations B+tree and B*tree) is the classic index structure used in pretty much all database products from Oracle to PostgreSQL and MySQL to MongoDB. The B-tree is not a spatial index. However, we mention it here since it would typically be used underlying a quad-tree index, and also just to provide a base level to which the other indexes can be compared.
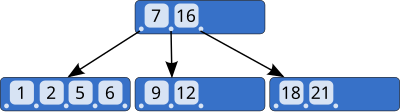
Figure 1 A B-tree
A B-tree is a generalized form of a binary tree. The key feature making it efficient for disk based database usage is the ability to store more than one record per node, and to have more than 2 children per node. This makes the tree flatter than a binary tree would be. Finally, allowing each node to be partially empty, allows for more efficient update operations, as records can be inserted and deleted into the empty space, and only infrequently is there a need to split or combine nodes.
In a B+tree the leaf node will contain copies of the records that in a simple B-tree would be stored only at the higher levels of the trees. This allows a sequential scan to complete purely by reading the leaf nodes without the need to jump "upwards" to fetch a single missing record. The other optimization is to make the leaf nodes a linked list, again allowing a scan to proceed directly to the next leaf node, without having to go "upwards" via the common parent node.
For more information:
https://en.wikipedia.org/wiki/B-tree
https://en.wikipedia.org/wiki/B%2B_tree
R-tree
The R-tree is the most common index structure for organizing spatial data / geometric objects. It can be thought of as "B-tree for rectangles". In fact, several basic features of a B-tree are retained, such as the tree structure itself, and splitting and combining of nodes.
For other shapes than rectangles the concept of Minimum Bounding Rectangle is introduced - this is a rectangle within which the shape can fit completely.
R-trees can be used for shapes of any dimensions, but currently 2-dimensional maps are certainly most common. The problem of how to map the Earth's sphere into a 2-dimensional surface is outside the scope of R-trees: If a 2-dimensional R-tree is used, then the 2-dimensional surface is already assumed to exist.

Figure 2 An R-tree is a hierarchy of Minimum Bounding Rectangles (here a 3D tree)
The idea of an R-tree is to group nearby objects and enclose them inside yet another Minimum Bounding Rectangle. These rectangles are again enclosed in larger rectangles, eventually leading to a root node: the largest rectangle enclosing all objects in the database.
Search
The input to a search operation is likewise a search rectangle. The R-tree index can now be traversed such that rectangles that do not overlap with the search rectangle are immediately pruned, while nodes for overlapping rectangles are traversed and overlapping leaf nodes included in the search result.
Descriptions of R-tree algorithms - including the linked Wikipedia article - are usually concerned only with finding the right set of Minimum Bounding Rectangles. However, when the actual shapes are not all rectangles, it doesn't mean that all shapes in this result set would actually intersect or be enclosed by the search rectangle. (Nor does it have to be the case that the search input is a rectangle either.) The basic idea with R-tree is still to efficiently find a superset of matching shapes, after which this set can be checked one-by-one with some other algorithm, which is different for each shape (lines, spheres, polygons). For instance, to check if two lines intersect, the equation
a1 x1 +b1 y1 + c1 = a2 x2 +b2 y2 + c2 (for valid ranges of x and y)
needs to be solved.
Insert / update
The different variants of R-tree structures differ mainly in how they build the index during inserts, and this can have significant impact on the structure of the tree and resulting efficiency. The differences arise in particular when nodes are full and need to be split. There is no single correct way to split the objects into 2 separate bounding rectangles, and furthermore computation to make the decision is expensive, leading to the use of simplifying heuristics.
The following picture show bounding rectangles in red, resulting from indexing the same 2D points with different algorithms:


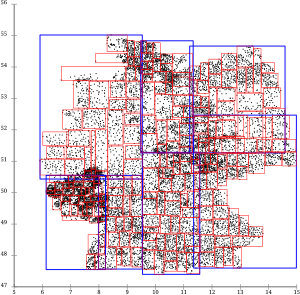
Figure 3 Effect of building an R-tree with different algorithms
The picture illustrates how the 2 first algorithms result in very long and narrow rectangles. This is clearly sub-optimal: A typical application would be searching for some small area in a particular location, say Berlin. With the first two indexes, one would a) have to retrieve several pages to get all those points in Berlin, and b) one would have to read a lot of unneeded data that happens to reside on the same pages even if its quite far from Berlin. The third R*tree index on the other hand seems to have grouped the points into rectangles which minimize the radius of each rectangle, usually exactly what you want.
To mention a few variants:
The R+tree modifies the R-tree algorithm such that the bounding rectangles for each node are non-overlapping. To achieve this, if an object is inserted that intersects the rectangles of 2 or more nodes, it is copied to both/all nodes.
As seen above, the R*tree uses an algorithm which results in relatively quadratic rectangles. In addition, as a different approach to re-balancing the tree it also removes already existing objects from the tree and re-inserts them, which may lead to objects becoming stored in different nodes than their original location.
To read more:
https://en.wikipedia.org/wiki/R-tree
https://en.wikipedia.org/wiki/R%2B_tree
https://en.wikipedia.org/wiki/R*_tree
Quad-tree
The quad tree is a simple index for a 2D space, which is based on the idea of dividing a rectangle into 4 parts of equal size, then dividing the resulting rectangles again, and again, for better granularity. This creates a search tree where each node has exactly 4 children.
The 3D counterpart to a quad-tree is called octree, it divides a 3D space into 8 parts.
A key benefit of the quadtree is that by labeling each sub-rectangle with the numbers 0 ... 3, it is possible to uniquely represent each area with a string of numbers. Whether stored as a string, integer1 or just bytes, this string of numbers is straightforward to store into a normal B-tree and rectangular areas can be searched with less-than or greater-than operations.
As a result, if a quadtree encoding is done on the application side, it becomes possible to use any common database such as MySQL or MongoDB, without the need to use any spatial features on the database level. With the increase in use of Amazon and other public clouds, and in particular PaaS services for data storage, the need for this kind of architecture is increasing.
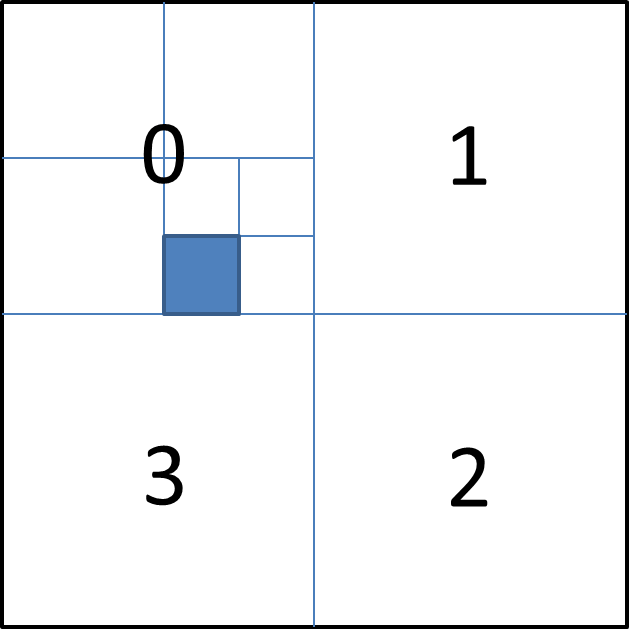
Figure 4 A quadtree dividing a 2D surface. The blue area is indexed as 023.
For instance, the blue rectangle in the picture above is indexed as 023. It can naturally be searched from a database simply as "x = 023". However, if you also wanted to search for the sub-rectangles inside that area, such as 0231 or 0233, you could search for "x >= 023 AND x Grid based
Quad-trees are a form of a grid-based spatial-index, but there can of course be other grids too, starting from a naive grid of rectangles refered to with (x,y) coordinates. Using such grids is straightforward, but the discussion then usually revolves around the problem of projecting the 3D sphere that is the world onto a 2D, often rectangular, surface. This gives rise to more elaborate forms of lattice, such as a Geodesic grid.
Apparently SQL Server spatial features are based on a Grid based index. I don't know how that becomes different than R-tree indexes.
For more info: https://en.wikipedia.org/wiki/Grid_%28spatial_index%29 and https://en.wikipedia.org/wiki/Geodesic_grid
***
This is what I learned by reading up on spatial data structures. If you have comments, or there's something more I should know, I'd be interested to hear.
- 1If storing as an integer, one would have to use numbers from 1 to 4, to avoid problems with leading zeros.
- Log in to post comments
- 39412 views
Another well-known spatial
Another well-known spatial index category, as well as the way to reuse the existing 1D B-tree implementations, is the B-tree over a space-filling curve (such as Hilbert curve).
The index choice depends on what queries are going to be issued for it, or /dev/null would make a great index :)
In the case of spatial indexes, there are many interesting types of queries. The obvious ones are point and range queries, i.e. what's in the given rectangle. But there are also nearest-neighbor, top-k, skyline and other more exotic things too.
Another interesting thing that happens with spatial indexes, is that they, at least in academia, tend to become aware of many properties of the model of the thing being indexed. For example, if a set of moving cars is indexed, then an index may not only process position updates and answer given range queries, but assign probabilities to query results too. I.e. if some object was updated long time ago, then the index knows its position with less certainity.
I came across the Hilbert
I came across the Hilbert curve on Wikipedia as yet another variant on how to balance the R-tree. The end result is still an R-tree but the insertion algorithm tries to break the R-tree into pages so that its objects are as close as possible on a Hilbert curve. Didn't realize it is also an obvious way to make things 1-dimensional. (Although, I like the quad-tree for its simplicity.)
I will probably blog more about use cases later, but in practice I'm looking into:
* geocoding: here the search is mostly against text, a point is the result.
* reverse-geocoding: input is (lat,long) and output is exactly one shape that contains it, like street address.
* within a rectangular area: Find all points, shapes, whatever that should be visible on this screen
* within a circle: Find all points, shapes, whatever within given distance from (x,y)
In practice applications are not so simple, for instance a reverse-geocoding application will asume that a vehicle probably is on a road, even if the GPS might suggest you are 50 m off :-) The application then has to choose your most likely location close to the point the GPS pretends to be at. Similarly there might be a time or speed dimension: We could assume the car is continuing in the same direction as a second ago (thus probably being on a specific lane, unless the driver is sleeping...) rather than having suddenly made a u-turn and changed direction.
This is why your index that includes likelihoods is very intruiging. I don't think practical implementations are there just yet (we are more concerned with continuous integration and other mundane stuff...) but in a few years I could see such structures becoming a hot issue.
references for reading
Hi, just finished my MSc thesis on spatial data structures (and an implementation in MariaDB) and though I could share some good references I came across.
* Shashi Shekhar and Sanjay Chawla. Spatial Databases: A Tour. Prentice Hall, 2003.
* Yannis Manolopoulos, Alexandros Nanopoulos, Apostolos N. Papadopoulos, and Y. Theodoridis. R-Trees: Theory and Applications (Advanced Information and Knowledge Processing). Springer, 1 edition, 2005.
In case you find it useful, the thesis text describes the algorithm details for some of these data structures http://tinyurl.com/bu2dah6
Thanks. Your thesis seems to
Thanks. Your thesis seems to be a great reading tip, both comprehensive and still understandable. Thanks for the link!
Is your work going to be included in MariaDB?
Thanks Hingo, I am really
Thanks Hingo, I am really glad with your comment, since this was one of the mains goals of the theory part of the thesis.
Yes, we plan to include it in MariaDB, but the code still needs some polishing. Due to the time devoted to writing the text itself, there is still some work to be done. Hope to see it merged soon!