So yesterday I introduced the newly committed HTTP JSON key-value interface in Drizzle. The next step of course is to create some simple application that would use this to store data, this serves both as an example use case as well as for myself to get the feeling for whether this makes sense as a programming paradigm.
Personally, I have been a fan of the schemaless key-value approach ever since I graduated university and started doing projects with dozens of tables and hundreds of columns in total. Especially in small projects I always found the array structures in languages like PHP and Perl and Python to be very flexible to develop with. As I was developing and realized I need a new variable or new data field somewhere, it was straightforward to just toss a new key-value into the array and continue with writing code. No need to go back and edit some class definition. If I ever needed to find out what is available in some struct, I could always do dump_var($obj) to find out. Even large projects like Drupal get along with this model very well.
However, as soon as you need to store this back into a relational database like MySQL, you hit a speed bump. For every time that I added a key to my array, I would need to go back and do ALTER TABLE, edit my schema definitions and possibly even re-populate some test data into the new table structure. This was fine when doing some demo in university, but a serious productivity killer as soon as I started to code for a living.
To solve this I sometimes just took the approach of storing all of my PHP objects into a single table with a key column and one more BLOB column that would store the output of serialize($obj). Now I could add and remove data fields to my array and there was no need to even touch the database layer as I did that. WIN!
Also, this makes me the inventor of key-value databases, no?
Anyway, it is with this background I was interested in the JSON HTTP interface for Drizzle. It is cooler and more sophisticated, but under the hood it does something similar to what I described above.
So, to test developing something agains this API, a natural choice would be to use HTML and JavaScript. Since I don't need any kind of client library now I can just use a XMLHttpRequest() object to connect directly to Drizzle. Of course, in the real world you wouldn't let your users connect directly to the database, especially as this currently doesn't support user authentication (if you load any of the auth_* plugins into Drizzle, JSON no workiee...). But as HTML5 and JS become an increasingly popular choice also for app development, doing this to connect to your own Drizzle on localhost this still seems like a realistic demo to me. And we will of course add authentication at some point too.
The full demo is attached to this article, see below. You also need the json2.js library.
So let's toss together a form in HTML:
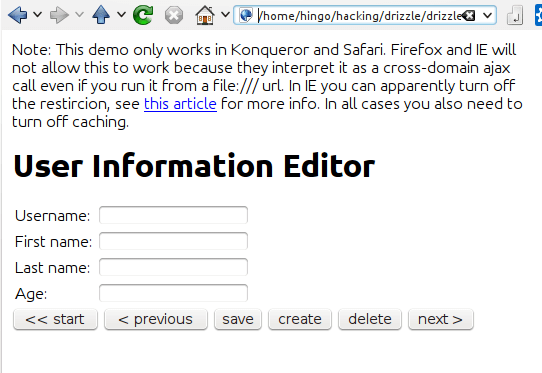
Now, all that is left is to implement some methods for the buttons. The main method to communicate with Drizzle looks like this, notice the trendy async call and callback function:
function json_query(method, query)
{
// clear old messages
document.getElementById("responseText").value = "";
var url = "https://localhost:8086/json?schema=json&table=people"
var xmlHttp = new XMLHttpRequest();
xmlHttp.onreadystatechange = function ()
{
document.getElementById("responseText").value = xmlHttp.responseText;
if( method == "GET" )
{
if (xmlHttp.readyState == 4 &&
xmlHttp.status == 200 &&
xmlHttp.responseText ) {
// Or use JSON.parse(), but this is the old skool way
var json = eval( "(" + xmlHttp.responseText + ")" );
populate_form(json);
}
} else if ( method == "DELETE" ) {
if (xmlHttp.readyState == 4 &&
xmlHttp.status == 200 &&
xmlHttp.responseText ) {
go_to_start();
}
}
};
if( method == "POST" ) {
xmlHttp.open(method, url, true);
xmlHttp.send(query);
} else {
xmlHttp.open(method, url + "&query=" + encodeURIComponent(query), true);
xmlHttp.send();
}
}
function populate_form(json)
{
var form = document.getElementById("myform");
for ( var i = 0; i
The populate_form() function takes care of the json object we get from Drizzle, and populates the HTML form fields based on matching the JSON key to the id attribute of the form field. Note that the form also has a hidden _id field where we store the key of our JSON record. Again, matching names.
If some field is not present (and also when it is empty) the populate_form() takes care of also setting the HTML field to an empty value.
Then what is left is to implement methods for each of the buttons. Here is the load() method that is used from the previous/next buttons, and go_to_start() too:
function load()
{
var id = document.getElementById("_id").value;
var query = '{ "_id" : ' + id + '}';
json_query( "GET", query);
}
Now we can see data loading into the form. WIN!
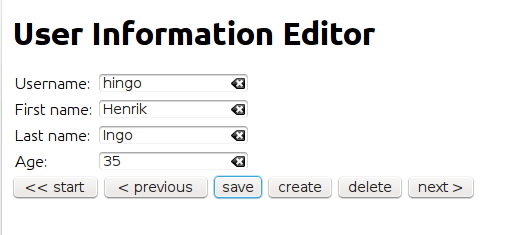
The above corresponds to this response object from Drizzle:
{
"query" : {
"_id" : 1
},
"result_set" : [
{
"_id" : 1,
"document" : {
"age" : "35",
"firstname" : "Henrik",
"lastname" : "Ingo",
"username" : "hingo"
}
}
],
"sqlstate" : "00000"
}
The above is pretty generic, but still not a one liner. In the end it is not that different from what you'd do with SQL too. You need a query, some communication and you need a few lines of code to move/bind data between the response object and form fields, and back.
But the big win comes from the flexibility of being schemaless. If you need to add some fields to the form, a HTML designer can just go ahead and do it. There is no need for the JavaScript developer to change any code (ok, that's not new) and there is no need for the DBA to edit an SQL schema definition. This is the benefit of schemaless approach.
Drawbacks? Yes. Key-value is key-value. You would see this for instance when using the previous and next buttons. They just blindly step forward and backward with _id values 1, 2, 3... If you have 5 records, and delete record nr 3, then you will see an empty form between 2 and 4. Using a pure key-value interface there is nothing we can do about this. We can just use one key, there is no knowledge of which record is "next" or "previous". (Of course, there is the exception that you can fetch the full table, but that's a bit heavy handed...)
We intend to work on range queries as a Google Summer of Code project (and more, blueprint coming up).
I will be speaking more about the HTTP JSON interface in Drizzle on Apr 13 at the Drizzle Day in Santa Clara.
- Log in to post comments
- 32553 views
{kind=link}
{kind=link}
Indexing
What are the best approaches for indexing serialized data in key-value store? Joins are not that important as data can me merged on application level.
It's a bit complicated, but
It's a bit complicated, but we are working on it at this blueprint: https://blueprints.launchpad.net/drizzle/+spec/json-server
More detailed spec will be available later this Spring.
In the past, I explored a similar approach on MariaDB using XML and virtual columns: http://openlife.cc/blogs/2010/october/mariadb-52-using-mariadb-column-s…
Thanks for the links i keep
Thanks for the links i keep following the topic as it is interesting and complex matter.